In a service-oriented architecture multiple product teams work together towards creating value for the customer. Backend teams need to ensure that the end-to-end functionality works, while frontend teams create an interface that exposes this functionality to customers, usually through web browser, mobile, or native applications.
With this setup, an entire project only moves as quickly as the slowest team. This makes it important for teams to utilize software delivery practices that encourage speed. However, some software teams operate on a “Scrum” delivery model, where a team will work on a set of stories for an iteration (2-4 weeks) between deployments. The way I’ve seen this work is that code is initially pushed to an integration environment (“staging”) - a segmented service that does not operate on customer data.
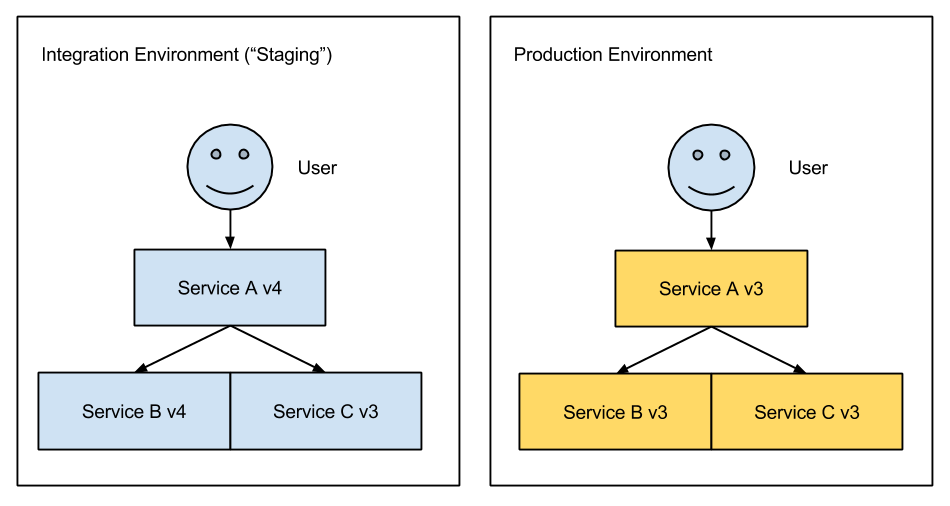
There are several antipatterns with this setup that I will explore in this article. I believe that delivery to an integration environment on a two-week cadence is simply not good enough to support larger-scale development. If you’re looking to organize development across multiple teams, your goal should be fast delivery to a production or production-quality environment.
Integration Environments Are Not Production
In an integration environment, the version of a service may not match the version of the service that is live in production. These services can have bugs that aren’t customer-facing and (worse) may depend on other in-development features, which can cause cascading problems. In the above diagram, service A and B are both operating at version 4, different than their versions in production (version 3). Will version 4 of A work with version 3 of B, and vice versa? You can’t tell - you have only validated version 4 of A and version 4 of B together. Without knowing this you cannot know whether it is safe to deploy A or B separately.
Using this model the only way to “make sure” that you can release is to give each service a ‘lock’ in the integration environment. Service A must upgrade to version 4 in the integration environment, followed by a production deploy of service A. Only after that can service B upgrade to version 4 in the integration environment. This slows production deployment across the entire organization to the combined speed that it takes for a service to be certified in an integration environment.
Additionally, suppose version 4 has a subtle non-functional bug that is not discovered during integration environment testing. Maybe 1% of all requests fail, or the system buckles under heavy load. Adopting the mentality that production has one solid version encourages the release of new features “all at once” rather than gradually rolling them out to customers. Slowly rolling features out gives you the ability to see how your changes are actually working and get targeted customer feedback before it is released to everyone.
Work done in an integration environment is mostly theoretical. To become real, code should be validated in production against real user behavior with real service dependencies.
Integration Environments Poorly Support Dependent Development Teams
While built on good intentions (e.g. “we don’t want to run unsafe things on a customer database”), in practice an integration environment will not have the fidelity of a production environment. Services can go down without warning and, depending on how thoroughly it had been tested before being pushed, might not work at all. It’s hard for me to get too angry about the inconsistent state of an integration environment – it is just extra hardware sitting around that, on failure, may or may not alert a human being. Issues in an integration environment will never be treated strictly better than production issues. However, if you rely on this integration environment to develop, a three-hour downtime can waste a day (or more) of productivity.
To get around issues with integration environments, I’ve utilized mocks – I wrote restmock to move a project forward when the corresponding service was not well-behaving. However, mocks do not fully replicate the customer experience. After developing a feature against a mock I was surprised to learn that it returned a ‘202 Accepted’ rather than a ‘200 OK’ and it would frequently take 5-10 seconds for a particular change to be persisted to the backend. This required a large amount of work to fix and a rethinking of the original user experience pattern. If done against a real service this discrepancy would have been discovered quickly, reducing re-work.
This isn’t to say that all mocks will have these issues. Creating mocks might be a good investment if your delivery timelines are far off enough that you’re not “wasting time” doing extra work to build a mock service. However, if your underlying issues are in service stability, you are going to have to tackle that problem eventually – mocks are just a bandaid that moves dependent development teams away from real customer behavior.
Deliver to Production Frequently, Opt Users Into New Features
The smoothest integrations for a service consumer are going to be against a production-quality service: it has both the behavior (no bugs) and the fidelity (no downtime) of a production service. As a development team for a service consumer, you can follow the same testing flows that a customer would. Ideally, you could sign up as a new customer (with your own credit card) and validate that everything worked by checking your in-development feature with a production-quality account.
To do this, services need to deliver changes to production quickly. What does this take? You need a lot of things that you probably wanted to have anyways:
- an automated deploy process
- zero-downtime deployments (you can never introduce a breaking change)
- a battery of functional tests to ensure that new code hasn’t broken anything
- comprehensive monitoring and logging to discover how changes have impacted non-functional requirements
Once you are delivering to production frequently, you quickly find that you need to adopt feature flags in order to push changes without keeping long feature branches alive. A feature flag allows you to change the application’s behavior based on a certain criteria and hide in-progress development from end users. There are a number of patterns out there for this: I’ll highlight GateKeeper and Etsy’s Feature.
On a past project I implemented these concepts in the following manner to determine whether a feature was on or off:
class Strategy(object):
"""
Business logic associated with whether or not a feature should be
displayed.
"""
def matches(account):
raise NotImplementedError
class LastDigit(Strategy):
"""
Feature is released to a user if the last digit of their account number
is the same as the one we're looking for.
"""
def __init__(digit):
self.digit = digit
def matches(account):
return (account.number % 10) == digit
test_users = ['testuser1', 'testuser2']
feature_strategies = {
'cool_feature': [LastDigit(1), LastDigit(2)]
}
def is_released_to(feature, account):
if account.user in test_users:
return True
if feature not in feature_strategies:
# This is a counterintuitive default behavior but prevents
# features from being "un-released" if flag checks are
# removed from the code before being removed from the
# configuration.
return True
for strategy in feature_strategies.get(feature, []):
if strategy.matches(account):
return True
return False
if is_released_to('cool_feature', account):
# do cool_feature things here
Here each check of is_released_to determines whether or not to show an in-development feature. Having a set of test_users that always saw new features easily allowed testing in a production environment. Another developer on my team changed the strategies mapping to be driven by a database and controlled through an adminstration panel, allowing us to quickly flip on and off features for users in production.
With a frequent delivery cadence, your testing strategy changes. Rather than trying to validate features in an integration environment that approximates a customer environment, you can validate them in an actual production environment. Service teams that don’t have downteam dependencies can rely on API contracts combined with feature flags for “full stack” testing.
In the following diagram Service A and Service B maintain their own test environments which exist in production and is the first place where new versions of their code go. To validate “cool feature”, the frontend team for service A tests with a few test users that the feature flag enabled, consuming the production version of service B. To validate “neat feature” before releasing in production, service B ensures that all new releases stick to API contracts and that business logic lives in the service (rather than the consumer). This combination of factors allows the service to change independently from its consumers.
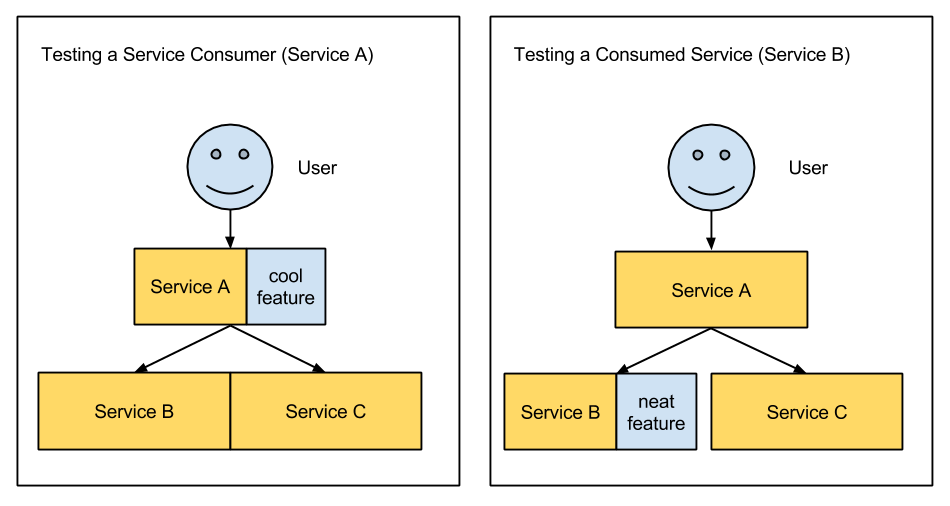
Of course, you still can’t have developers do boneheaded things in production – they can’t have permission to wipe out production data. By taking “test on accounts in production” as an end goal, you optimize for the common case - most small changes will be safe an harmless - rather than the uncommon case - a change that breaks everything and causes customer impact. Choosing developing and testing in production as an end goal does not mean you are any less serious about ensuring customer safety – it just means that you need to take alternative steps to getting there than total isolation.
Conclusion
Continuous integration was originally intended to break the practice of developers introducing bugs when integrating long-lived feature branches back into a ‘mainline’. When multiple teams of software developers build features together you have many of the same challenges, except that now the silos are between teams instead of individuals. Teams need to continuously integrate with each other so that changes pushed by a service team can be quickly consumed. The best way to achieve continuous integration between multiple teams is through frequent production deploys and with in-development features segmented by user, rather than environment.
Comments
I hope you found this article helpful – it is my attempt to draw some conclusions from practices implemented by industry leaders. Here are some resources I found helpful in putting this together.
- Netflix Operations: “Each engineering team is responsible for coding, testing and operating its systems in the production environment.”
- Etsy: “We push it to our staging environment, which is our production environment. It’s the same environment. It’s just to a version ahead and so no users hit those servers; it’s just us”
- Facebook: “When a test goes out we look at the data immediately and adapt the products quickly. We do this on a daily basis. This cycle of iteration is the engine of progress and the people who use Facebook are not just the beneficiaries but are also intimately a part of the process.”
Beyond the arguments that I’ve already used I believe that integration environments are a symptom of harmful team specialization (mutually exclusive “dev” “ops” and “qe” buckets) and that their presence encourages people to think of quality as an emergent property of the process rather than their job. Quality comes from everyone working to bake it in to everything that they do and not from management applying the right processes until quality “falls out”.